INTRODUCTION
As the world advances at a fast pace, virtual generation continues to develop. As it is one of the emerging international locations, Indonesia additionally faces the growth of digital generation innovation.1 There are many facts available stating the wider application of technology in a corporation. There was rapid development of information and technology in various businesses including healthcare offerings.2 Scientific facts are constantly explosive, and there are demanding situations for data management, storage, and processing.3 Efficient data acquisition, processing, and intake methodologies have been areas of top-notch interest for many years throughout business enterprises.4 Rich source of facts can enrich the knowledge of ailment mechanisms and better health care.5
Big data refers to huge and complex information sets which might be beyond the capability of conventional control systems to save, control, and manage.6 Big data applications represent numerous possibilities to enhance the performance of healthcare. 7 Big data can efficiently lessen fitness care troubles including the selection of suitable remedies, improving the fitness care machine, and so forth.8 Big data in healthcare refers to massive and complex electronic fitness datasets that they are difficult to manipulate with traditional software, hardware, information management tools, and techniques.9
Big data creates demanding situations in information size, transfer, encryption, storage, evaluation, and visualization. Healthcare relies on medical information on the method of selection. Large records analytics may be used to reap treasured facts from all forms of resources which might be too massive, raw, or unstructured in healthcare.10 Big data analytics applications in healthcare take the benefit of extracting insights from statistics for higher decisions making through analyzing the significant amount of records, from specific information resources, and in diverse codecs.9 Big data analytics has the potential to improve healthcare by using institutions and understanding styles and traits within the scientific data.11
Healthcare studies have been growing exponentially in the past few years. In developed countries, the healthcare industry offers massive volumes of digital health information which includes cardiovascular disease.12 Big data analytics can be used to achieve treasured facts from large and complicated datasets along with cardiovascular disease to enhance scientific treatment and healthcare.10 Cardiovascular ailment is one of the services in healthcare and is used as a component to facilitate the method of documenting scientific facts.13 Structured healthcare data are a vital useful resource for healthcare informatics research in predictive modeling. Massive scientific records have a large analytical capability that may be used to provide effective solutions for problems in the healthcare domain.14
LITERATURE REVIEW
Big Data
Big data typically refers to the considerable volumes of facts that the old information tools and practices are not prepared to address and presents extraordinary possibilities to strengthen technology and inform aid control via records-intensive approaches, and massive records technologies are permitting new varieties of activism environment within the procedure.15,16 Big data has six defining attributes, which are volume, range, velocity, veracity, variability and complexity, and value. The term quantity represents the importance of the information; variety is the structural heterogeneity in a record set; velocity is the fee of producing facts; veracity is the unreliability inherent in records resources; complexity represents the version in statistics flow price; and fee measures the facts extracted from historic incident statistics units for highest quality manipulate choice.17
Big data has the functions that are high dimensional, heterogeneous, complex, unstructured, incomplete, and noisy which makes it possible to collect precious statistics.18 The main resources of big data in healthcare are administrative databases, scientific databases, electronic fitness file information, and laboratory statistics systems information that can improve healthcare by using institutions and knowledge styles within the scientific statistics.19,20
Big data analytics
Massive facts analytics describe the procedure of accumulating, organizing and studying large statistics to discover styles, unknown correlations, market trends, personal alternatives, and other valuable facts that could not be analyzed with traditional tools.21 Big statistics analytics is a hard and fast technology and technique that requires new types of integration to discover hidden values from huge statistics which can be distinct from the standard ones, greatly complicated, and of a big scale.22
The commonplace varieties of big facts analytics include predictive, diagnostic, descriptive, and prescriptive analytics to extract exceptional styles of information for one-of-a-kind purposes.23 Huge records analytics in healthcare is hard and fast type of methodologies, tactics, frameworks, and technology which are used to transform facts into meaningful as well as useful records. These sets of information are used to make the more powerful selection methods for healthcare.24
Big healthcare data
Massive healthcare information includes huge collections of statistics from numerous healthcare foundations observed through storing, handling, reading, visualizing, and turning in facts for effective decision-making. Huge healthcare information may be dependent, semi-structured, or unstructured22 and can be received from number one sources (medical selection aid structures, electronic fitness records, etc.) and secondary assets (laboratories, coverage organizations authorities sources, pharmacies, and so forth.).25
Collection, agency, annotation, storage, and distribution of big data are vital activities in biomedical, medical, and translational discovery strategies. Massive healthcare records have the capacity to improve diagnostic signs and symptoms, predict epidemics, advantage precious understanding, avoid preventable sicknesses, reduce the fee of healthcare, and enhance the excellence of healthcare.26
METHODS
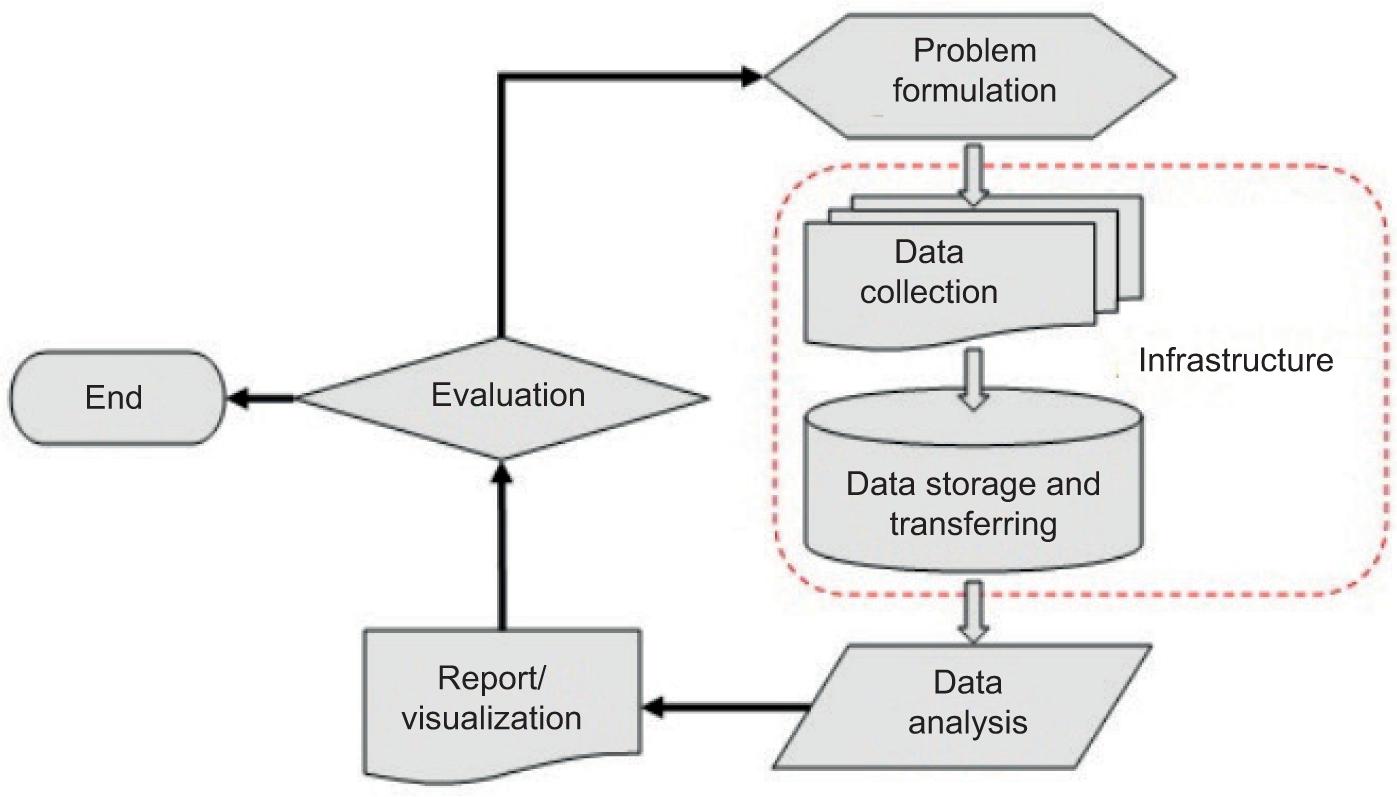
Big data analytics refers to the strategy of analyzing a large extent of statistics accrued from numerous sources in an unstructured, semi-dependent, or based form with the aid of the use of special analytical strategies.27 The common styles of large facts analytics are predictive, diagnostic, descriptive, and prescriptive that are implemented to extract extraordinary styles of know-how or insights from huge facts that can be used for exclusive functions relying upon the application area.23. Figure 128 indicates the stages of the study.
FIG 1. Research stages.
Big records analytics includes stringent analytical methodologies and gear which comprise correlations, cluster analysis, filtering, selection bushes, Bayesian evaluation, neural community evaluation, regression evaluation, and textural evaluation.29 Table 130 indicates the method of huge information analytics that consists of numerous strategies.
TABLE 1. Big data analytics process.
| BDA step | Critical question | Epistemological challenge | Possible guidance |
|---|---|---|---|
| Acquisition | What records do I need? What kinds of datasets which might be used to decide? |
Sampling | Observe statistics summarization, graphical representation, measurement discount (e.g. PCA), and outlier detection |
| Pre-processing | How the datasets may be represented and processed without falsification or understanding loss? | Quality of data | Make sure multi-expert and multidisciplinary participation in data reduction and choice hint and observe all levels of extraction, transformation, loading, and merging for completeness, correctness, and consistency |
| Analytics | Which techniques to use and what rules govern conclusions from those datasets? | Knowledge discovery | Map the constructs of analytics for theoretical ideas and expand or practice framework for preference of techniques consisting of mining, system mastering, records, or models |
| Interpretation | The way to interpret such conclusions? | Interpretability and reliability of estimation | Develop or practice the theoretical framework for interpreting the result |
RESULTS AND DISCUSSION
Big amounts of records, pushed through document keeping, regulatory compliance and necessities, and patient care are generated using healthcare. Healthcare used massive statistics analytics to investigate data to get valuable facts to improve healthcare performance. Large information analytics can help early detection of disorder, correct prediction of disorder, identification of deviation from the healthy kingdom, and detection of fraud.
RapidMiner is a software program that we use to investigate facts with algorithms to get useful statistics for healthcare. We analyzed the records using a classification technique and a choice tree set of rules to classify cardiovascular sickness which may be used as predictive and prescriptive analytics. Predictive evaluation predicts what might take place at the end and prescriptive evaluation recommends actions that may be taken to act on those results.
We used cardiovascular sickness datasets that had been accumulated at the moment of scientific examination in this research. There are three styles of capabilities on these datasets specifically objective (actual statistics), examination (results of the clinical exam), and subjective (statistics given by the patient). This dataset has 70,000 rows of patient records and 12 attributes of facts for patients and the outcomes of the clinical exam. Following are the attributes of the cardiovascular disease datasets:
-
Age: authentic records of approximate patient’s age (in days).
-
Height: facts about the patient’s height (in cm).
-
Weight: factual records of approximately affected person’s weight (in kg).
-
Gender: authentic facts of approximately affected person’s gender (1 is a female and a couple of is a man).
-
Systolic blood stress: effects of clinical examination from patient’s systolic blood stress (in mmHg).
-
Diastolic blood pressure: consequences of scientific examination from affected person’s diastolic blood pressure (in mmHg).
-
LDL cholesterol: outcomes of scientific examination from affected person’s LDL cholesterol (1: ordinary; 2: above every day; three: nicely above every day).
-
Glucose: effects of clinical exam from patient’s glucose (1: normal; 2: above ordinary; 3: properly above regular).
-
Smoking: statistics are given via the patient about smoking (zero: non-smoker; 1: smoker).
-
Alcohol consumption: information is given via the affected person’s approximate alcohol intake (0: no longer an alcohol drinker; 1: alcohol drinker).
-
Physical hobby: records given through the affected person about physical activity (zero: no bodily interest; 1: have physical pastime).
-
Presence or absence of cardiovascular disorder: records from analytics of the use of a decision tree set of rules about the presence of cardiovascular sickness (0: absence; 1: presence).
Within the preprocessing section, we remodel raw data right into a beneficial and efficient layout. We explore our cardiovascular disease datasets for cleansing of facts. In this phase, we identify lacking attributes and blank fields, cleaning or change lacking values, replica or incorrect statistics, and inconsistent facts. We examine the facts for completeness, correctness, and consistency. Intricate statistics that have not been recognized and analyzed can produce deceptive effects. This section is crucial to produce accurate outcomes with the aid of processing the analyzed facts.
After preprocessing the segment, we put the information into RapidMiner to start the analytics. Before analyzing the information, we set the characteristic type based on the facts type. We have to set the attribute kind effectively to be able to produce correct results. We examine the information on the usage of a decision tree set of rules in RapidMiner to do analytics. Choice tree set of rules is used to categorize the presence or absence of cardiovascular ailment. First, we gather the information using a choice tree algorithm to generate the guidelines and selection tree and then analyze the effects.
The decision tree algorithm offers a choice tree to find the classification rules from the facts. In that decision tree, the foundation node or predictor is ap_hi (systolic blood pressure), internal nodes are different attributes that carry the information and the leaf node is the aerobic (Presence or Absence of cardiovascular disease). The result of the decision tree from cardiovascular ailment is used to explain or understand the result from classification based on the alternative attributes such as the root node and inner nodes that determine the presence or absence of cardiovascular ailment because of the leaf nodes.
The gain of a decision tree may be defined as rules or descriptions from a decision tree. The rules or descriptions from a decision tree is an if–else statement. Figure 2 shows the rules from the decision tree.
FIG 2. Decision tree rules.

These rules are generated from the selection tree beginning from the foundation node or predictor till the leaf node. Those policies deliver a clean analytical view of the result from the selection tree. We will understand all the manners from the selection tree using those regulations.
After the selection tree is generated from the cardiovascular disease datasets using RapidMiner, we additionally check for the performance. We carry out performance testing to determine whether the analyzed information is accurate or not. Table 2 shows the performance testing result.
TABLE 2. Result of performance testing.
| Accuracy: 72.17% | |||
|---|---|---|---|
| True 0 | True 1 | Class precision | |
| Pred. 0 | 26319 | 10780 | 70.94% |
| Pred. 1 | 8702 | 24199 | 73.55% |
| Class recall | 75.15% | 69.18% | |
The overall performance testing indicates the extent of accuracy, class precision, and sophistication. We acquired 70.17% for the level of accuracy in the category. The elegance precision for prediction 0 or Absence is 70.9% and the magnificence precision for prediction 1 or Presence is 70.6%. For the class do not forget, we acquired 75.15% for actual 0 or Absence and 69.2% for real 1 or Presence. The measured degree of accuracy, precision, and do not forget achieved high performance. This means that a class progressed the efficiency and effectiveness of cardiovascular disease.
Big data analytics with category method and the usage of choice tree algorithm for the cardiovascular disorder can improve the performance and effectiveness. The selection tree presents the cause of the hidden sample from the records so that we can apprehend the records that we get from the facts using a choice tree algorithm. We also examined the effects from a category using a selection tree as predictive or prescriptive analytics. Healthcare can predict an affected person who has a cardiovascular disorder and provide preventive care to the affected person. Big facts in healthcare are vital, right here is the opportunity for healthcare that implemented big information:
-
Improved preventive care – The use of analytics in healthcare scientific records can improve prevention for the affected person. With big facts analytics, healthcare can seize, analyze, and examine affected person signs. Healthcare is advanced with preventive care that can treat the patient properly and prevent or postpone the illness and disorder. As in the research, we classify cardiovascular sickness so that healthcare can understand the right remedy for the patient to be more powerful and effective.
-
Improved diagnostic symptoms – By doing large statistics analytics, healthcare has advanced with a thorough diagnosis of symptoms in patients. Diagnostic signs are a system to decide patients with the disease. Improved diagnostic signs and symptoms are gathered from the hidden sample of patients’ facts. With advanced diagnostic signs and symptoms, healthcare can diagnose the patients with greater efficacy. Within the studies, we classify cardiovascular disorder having numerous attributes to decide the sickness so that healthcare can diagnose the affected person with greater accuracy from their signs.
-
Reducing healthcare cost – Big data can assist in reducing the fee of imparting clinical treatment. Massive statistics analytics for healthcare can carry valuable data to improve their gadget through discovering associations, knowledge patterns, and developments within scientific records. With analyzed information, their improved scientific remedy can examine and diagnose the patient to a greater extent. With this effective and efficient healthcare system, a patient pays less and gets an accurate remedy than the normal scientific treatment. Further, the presence and clarity of presidential guidelines and laws become necessary to reduce uncertainty or dangers related to the usage of databases and shield the purchaser’s hobby.1
CONCLUSIONS
In this research, we used category techniques with a decision tree algorithm for cardiovascular disease datasets. The outcomes from this research are the decision tree and guidelines that classify the presence or absence of cardiovascular disease. We additionally take a look at the overall performance to decide whether the analyzed information is accurate or not. We acquired 72.17% for the level of accuracy in type. The elegance precision for prediction 0 or Absence is 70.94% and the class precision for prediction 1 or Presence is 73.55%. For the class recall, we obtained 75.15% for true 0 or Absence and 69.18% for true 1 or Presence. The analyzed information can be used for predictive and prescriptive analytics. Big data analytics with classification methods using decision tree algorithms for cardiovascular disease can improve the efficiency and effectiveness of healthcare. Healthcare can treat a patient who has cardiovascular sickness and offers preventive care to the patient. With the help of big facts, healthcare has the opportunity to improve better healthcare, which includes advanced preventive care, progressed diagnostic signs, and decreased healthcare prices. In this research, classification methods using the choice tree algorithm can be used for other datasets and can be advanced by combining or evaluating the use of different category algorithms to get better effects.
ETHICAL APPROVAL
All procedures were conducted with allowance and followed the regulation of all parties involved as objects in this research, and also with the permission of related universities.